Chess Engine - (Part 1)
Pretraining Network on 18.6 Lakh moves
This is first in a series of blogs covering this project. TL;DR see this Github repo. Also for all you who do not understand the Indian number system just read this wiki.
This is going to be a fairly long blog since I haven't written in quite a while. Now that I have quit my job at Shipmnts and am still looking around, I am thinking I'll just enjoy not working for a while and work on something of my own. Let's see how this goes. If you have any freelancing work, contact me on my LinkedIn.
I built this over my Diwali break and took about 20 hrs of training of different models to test. The challenge is to spend \(<30 \text{hours}\) on coding and building and a few hours blogging and supporting material. I have been using vast.ai and it has been super cool to finally get machines that I can use to train and play around. The blog is in two parts:
☄️ On Intelligence
Compute, you nasty bitch: I started this writing this code atleast 5 months ago and stoped because of lack of compute power. In hindsight I now realise that having compute is more important than anything else, because if you cannot run this thing you won't even understand the kind of bugs you are yet to encounter on your way. If there is any project that you need to work on, it is crucial that you run the code first on CPU and then figure out a way to run the same thing on GPU. Best option is writing a goddamn shell script to handle everything end to end. If you or your company cannot figure out a way to get sufficient compute, you will always be behind. Never forget the bitter lesson.
Rant aside, what is it about intelligence that you can find from doing this project. One measure of intelligence is the amount of information that can be compressed. Quoting directly from the Hutter Prize website:
Being able to compress well is closely related to intelligence as explained below. While intelligence is a slippery concept, file sizes are hard numbers. Wikipedia is an extensive snapshot of Human Knowledge. If you can compress the first 1GB of Wikipedia better than your predecessors, your (de)compressor likely has to be smart(er). The intention of this prize is to encourage development of intelligent compressors/programs as a path to AGI.
The size of raw dataset is \(~1.1GB\) which is then compressed get a zipfile of \(~360MB\). If this is considered as baseline then our model needs to compress all this information in a smaller file size. However with the Neural Networks we cannot get a lossless compression, because of the probabilistic nature there has to be loss in the compression, and I think it is fine to do that because it compensates this by providing an inbuilt search engine as well. Given this set of moves we take the action that most likely leads us to win. In practice the baseline model with parameters given above gives a \(~24.2MB\) for pytorch model, far lower than the compressed ZIP. Thus making it smart(er) in a different way?
On the topic of compression there are other ideas like Kolmogorov Complexity (KC), the smallest computer program that produces a certain object as an output. For eg. consider a string like \(\text{0123456789012345678901234567890123456789 (36b)}\), it is far easier to write code like \(\text{print([i in range(10)]}\times 4)\text{ (25b)}\), thus we say that the KC of program is lower. Another way to look at this is as follows:
Kolmogorov defined the complexity of a string \(\text{x}\) as the length of its shortest description \(\text{p}\) on a universal Turing machine \(\text{U(K(x))} = \min\{\text{l(p):U(p)=x}\}\)
The way to include KC in the chess problem is to say what is the shortest description of all the games that the model has seen. In clarity KC is a hypothetical concept and not practicaly applicable because it allows for programs that can run for infinite time (read Halting Problem). If you are interested in reading more, search for "Solomonoff Probability", "Levin Search", "Martin-Loef Randomness".
📦 What is this?
Current neural chess engines, specifically AlphaZero / MuZero, primarily are search engines that travel over a tree to identify best bets over a certain fixed future (depth value \(k\)). It plays with itself and tries to assign expecation for each and every board configuration given a past. The task of neural network is now to become value function. However, it is super hard to code and build such system from scratch and it does not include the millions of games already played.
Now there is a reason why you would not want to have any prior (previously played games), because this can help with something called emergent behaviour. This emergent behaviour can help in solving problems and getting solutions that previously were not thought, from AlphaGo's Move-37 to finding bug in code (driving on a box). However \(>70\%\) of the problems in this world are already very efficient and what needs to be done is speed up the process, which requires massive use of prior.
Muzero and AlphaZero showed how we can utilise self play and AlphaGo showed how we can use priors, thus this project is closer to AlphaGo than AZ. Now if there already exists AlphaGo (extend to AlphaGo for Chess) why do we even need this? All these algorithms and other supervised methods utilise board state. But most of the problems in this world, we may not be able to generate a perfect board state to feed into the model. Consider another RL problem like Shipping where creating a perfect board state is impossible.
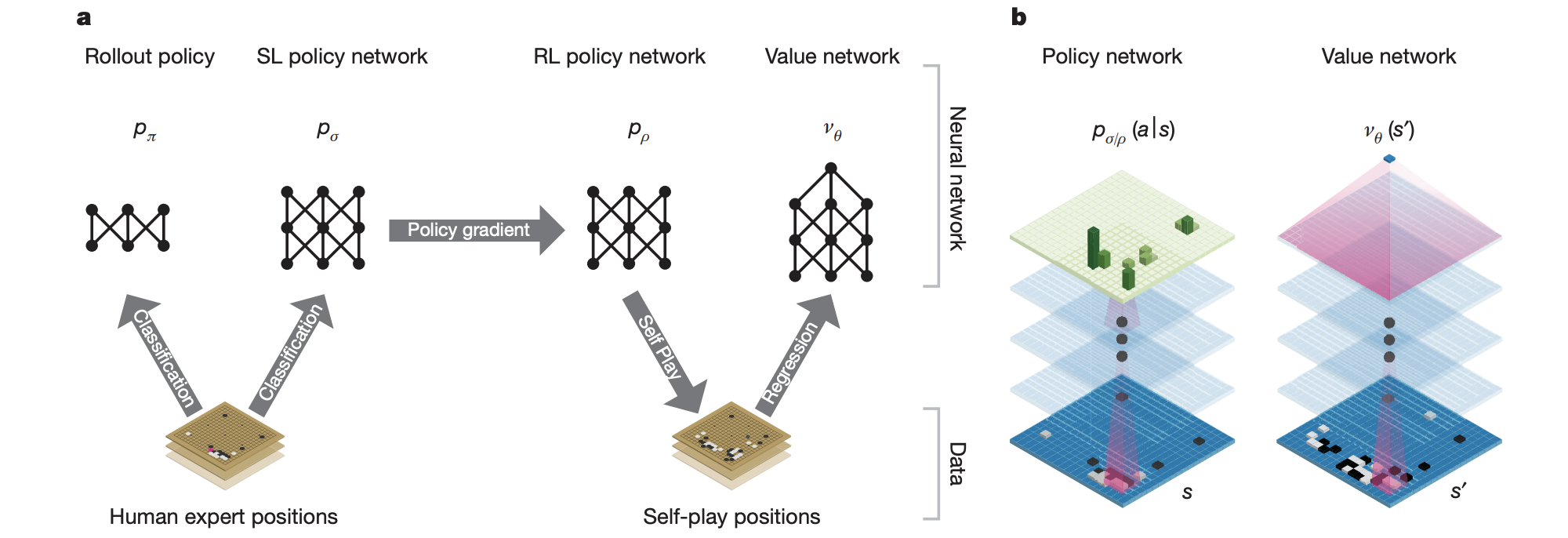
Training method (left) and network (right) of AlphaGo. Note how is utilises the complete board state and internally only process it.
Now that the perfect board state is thrown out of the window, how do we train a chess engine. One interesting thing I have noticed in great chess players is that they have a perfect memory of board moves as if they are poems to them. See this video of Magnus Carlsen remembering games. If they can just remember things, why can we not make a neural network just remember the moves and expect that it has an internal representation of the model.
Why not make a neural network just remember the moves and expect that it has an internal representation of the model
👾 My Solution
So I took the best model that has the capability of remembering things aka the legendary transformer. I train an transformer on moves as if it is a langauge, such that it would be able to identify patterns in it. To get the data, I scraped the links on pgnmentor.com, which gave \(31,67,846\) games and removing the corrupted ones gives \(31,66,353\) games. Note that there can be duplicates in this and I have not checked for those. All these games give an approximate \(18.6 L\) or \(186 Mn\) moves. This means that model has to learn patterns in all these tokens.
I use huggingface's amazing transformers library, more specifically a GPT-2 model. The trick was encoding all the moves, there are multilpe notations for each move like figurine ("♘f3 ♞c6") or algebric ("Nf3 Nc6").
🗣 Vocabulary
There are multiple ways to build a vocabulary. One method is to use the PGN notation, in this case we take all the units as "N"(knight), "R"(rook), "B"(bishop), "K"(king), "Q"(queen) and pawns are given empty san notation.
There are just too many tokens to accurately find, moreover the super niche ones (like en-passant) would occur only a few times making distribution too skewed. One way is to simply pass it through a sentencepiece tokenizer, but that does not work with the interactive gaming style we need.
In short this is too stupid, is there a better way to do it?
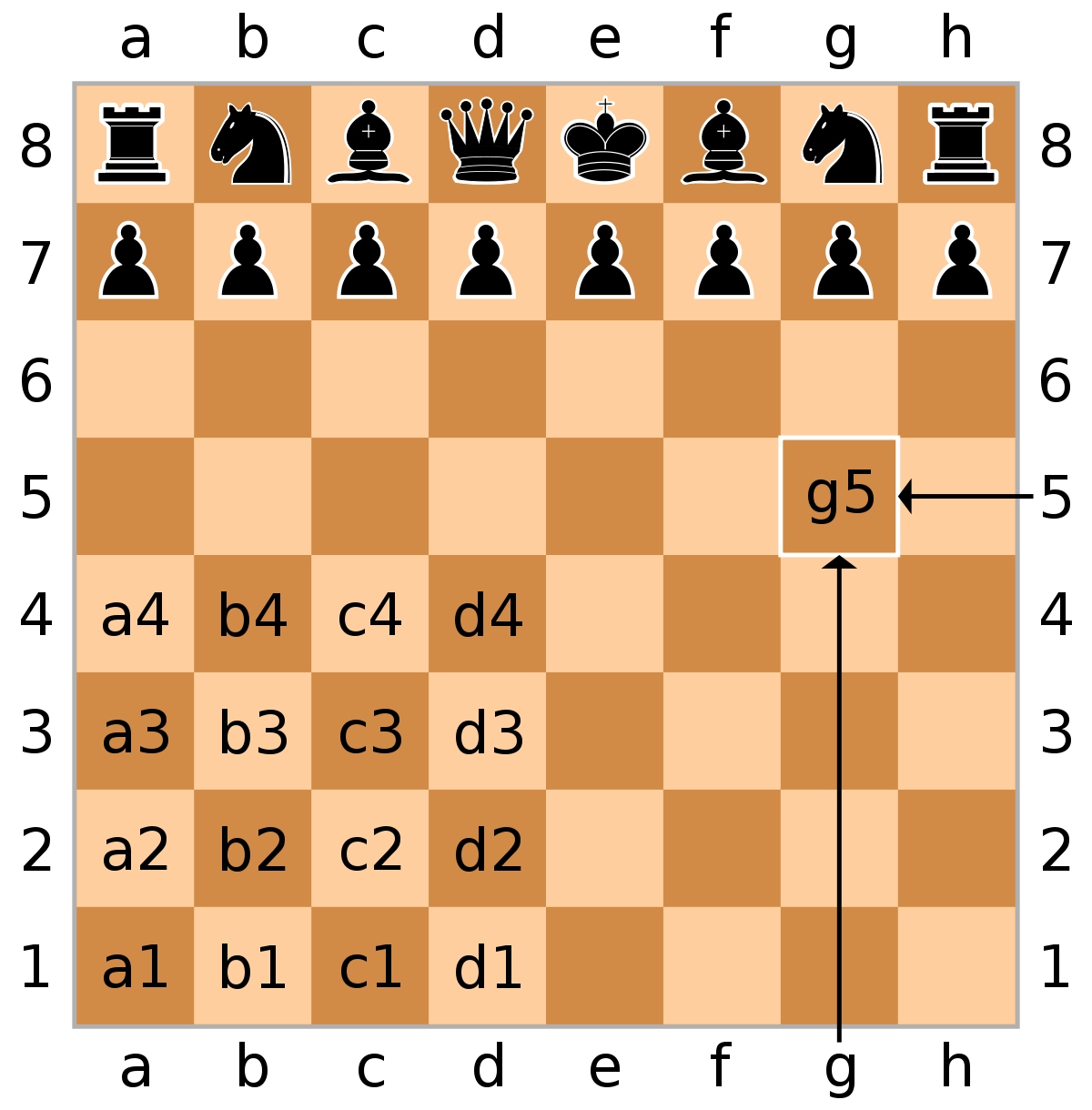
The board notation is given as above, we can then extend it to fill all the locations in the board. You can then simply say that any move irrespective of the unit has a starting box and a destination box.
🗣 Vocabulary 2
A simpler method is to simply tag a starting box and a destination box ie. if a unit moves from A1 to A2 we
denote the move as A1A2 and so now all we need to know is all the possible moves on a board. It turns out that
the total possible moves on a chess board is \(1792\). In this method we have to drop the unit information, which
is fine because library like chess already takes moves as (from_box,to_box). Again
continuing my assumption that model would be able to have an internal representation of the board and units and
movements. For eg find the list here:

Sample sequences shuffled. Note \(0\) means new game just like GPT-2 and not use any special attention matrices. In my experience it does not work well.
🤸🏻♂️ Training
The training is super straightforward, we continue with the GPT-2 training style and assume that the input is
a very long string and at the start of each game we add a [GAME] token which acts like a delimiter.
For more details read the code on Github repo.
The model has the following properties {"n_embd": 128, "n_head": 8, "n_inner": None, "n_layer": 30, "n_positions": 60,
"beta1": 0.9, "beta2": 0.95, "lr": 0.0001}. Training is performed on two 1080Ti with combined GPU memory of
\(~22GB\).
Since initially developement was done on my laptop I added an IterableDataset and for shuffling added a
buffer. Once this buffer was full we split the tokens into sequences, shuffle them and yield those. Next task is to
convert this to a conventional Dataset and see how better the results get.
🎛 Experiment
First task is to see if a model can actually learn and it turns out it eventually does. Following are the lessons learned:
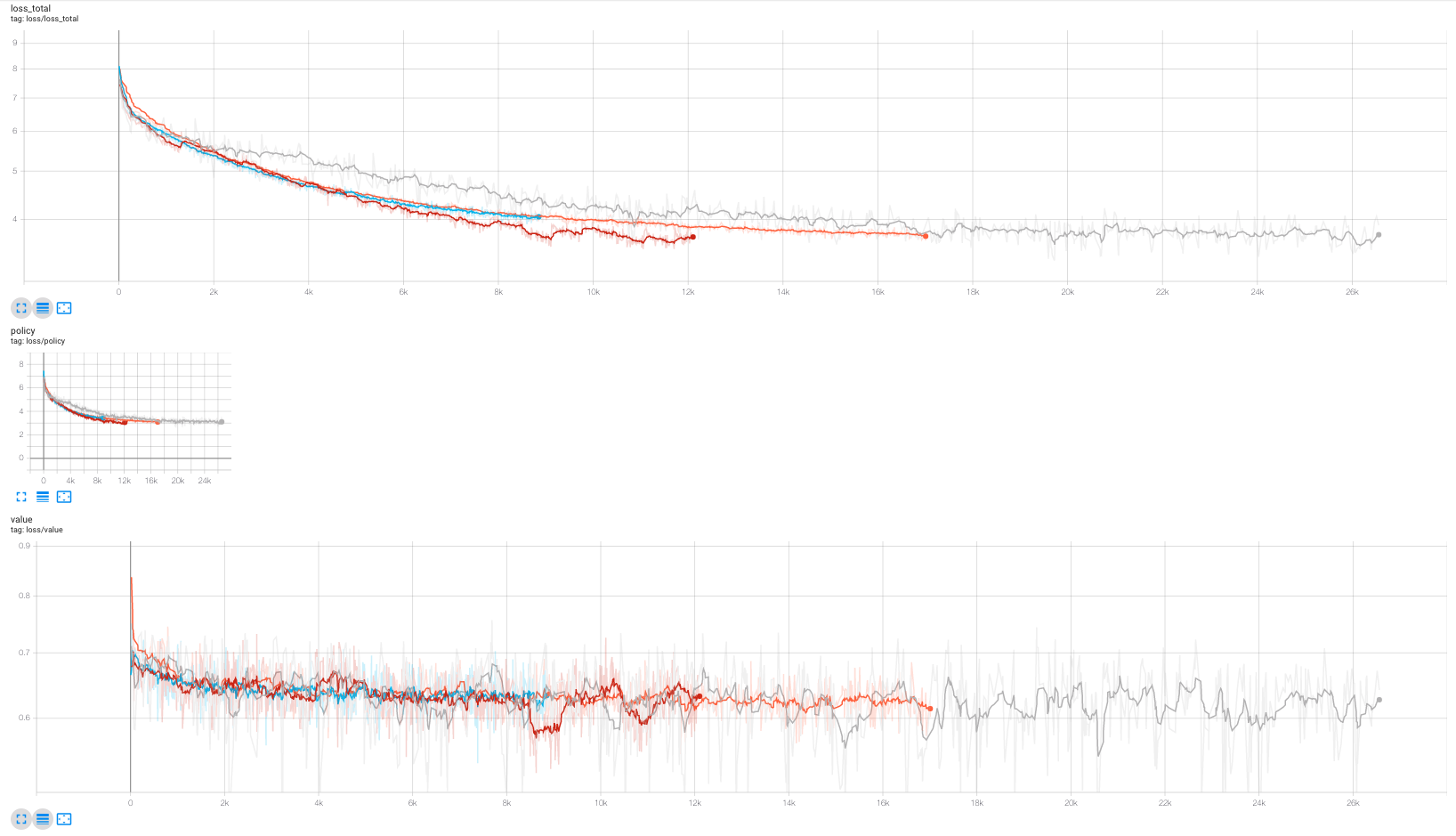
Tensorboard for training 3 models. Grey represents buffer size of \(55555\), red is larger model \(~3\times\) parameters of baseline parameters and buffer size of \(1000000\). Orange represents fully loaded dataset same arch. as Grey. Though the larger model trains quicker the loss function is rougher and there is a slight benefit. Grey was trained for 3 epochs whereas others were trained for 1 epoch. (there was as bug in IterableDataset which caused number of samples to be lower than fully loaded)
Validatation
The first part of validation is to include a tournament system to calculate the ELO ratings. For this I have written a single script that takes two models and competes them against each other. For a larger tournament system will need to write a bash script that manages this script 😂. This is still Todo.
➡️ What Next?
First step is to evaluate the models using accuracy and other through competition. This part is much slower and will take 3-4 days to complete in automated testing. In another method I will create the large model with atleast \(~10\times\) more parameters (\(~1/2\) the size of GPT-2) and see how it performs (training will take another 1 day).
I need help with writing automated tests. You can raise a PR on repo, there is also a Todo list on things that need to be completed. Again a plug, I am currently looking for freelancing work and if you have something connect with me on my LinkedIn.