Teaching Machines Rules and Algorithms
Cellular Automata Learning Neural Network
🦠 This particular Coronavirus strain (SARS Cov2) is the biggest calamity to happen to humanity since World War 2. It has put all of us in our homes without anything interesting to do, so I decided to take time and try out some whacky ideas. But being limited by compute power of a Google Colab I needed to try out something simple, quick and low power, not training some giant neural network based language model for Covid-19 Kaggle challenge.
Like always I go on a bit of writing before getting to the point so TL;DR.
📦 Software 2.0
Machine learning is good with cases where we have large datasamples and we need to generate algorithms from it, though very important problem it's still has not entered the software industry as much as a developer would want. The few changes that have happened is that now I have to write an API query to Google and they run the networks.
But this is boring and not where it should be, conventional software programming still dominates most of the things we do. I have a theory why that is, the current state of machine learning algorithms have gone from data ➜ algorithm but all the other software goes from algorithm ➜ data and we do not have a way to teach network rules.

An overview of how the business rules, you can look at the complexity that they have and ignoring the data flow piece there is a possibility to convert this into Neural Engine
The reason I bring up business rules is because that is what I do professionaly, building integrated systems that take in documents at one end and create business metrics at the other end. I had an idea that most of business rules can be converted into giant if/else statements and you just need a smart enough language to load that run those, this can be loosely interpreted as Flow-based programing where the data flows through and rules can be easily understood and created without writing a JSON for each complex rule.
🤖 PoC: The idea of cellular automata
While my readings I came about two practical applications of neural network to perform tasks that are more software oriented. Both of them can be seen in Differentiable Neural Computers, one is long term copy pasting the other is shortest path finding on a graph. These are practical examples of a copy-pasting mechanism and Dijkstra's Algorithm, though still not the perfect solution but better than the rest.
I needed something that was simple enough, and I came across Conway's Game of Life something that is very simple but can generate some amazing patterns. I was not interested in generating the specific grids but more on the simplicity of it's algorithm which has three simple rules
This was good enough to implement and wrote a 20-min gist: It generates sample like this:
starting top right go line by line
❄️ Building a Network
All the main code is uploaded on this colab notebook. In short there are a few ideas that I had
Conv-Conv-Deconv-Deconv structure I have a Conv-Deconv-Conv-Deconv structure
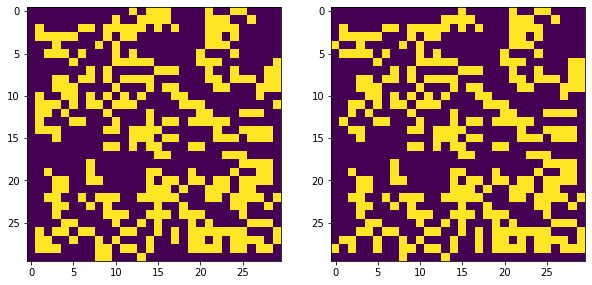
Quick training result left: target, right: predicted
I got some good results after a quick model training I started getting good results. But there needs to be a good robustness test, so I tested on the following things:
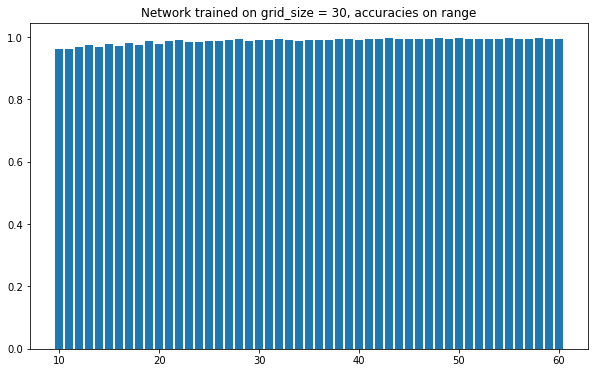
Surprisingly there is no change on results and in fact it performs better on larger grid sizes

And no it is not over-fitting to give just one value; left: target, right: predicted
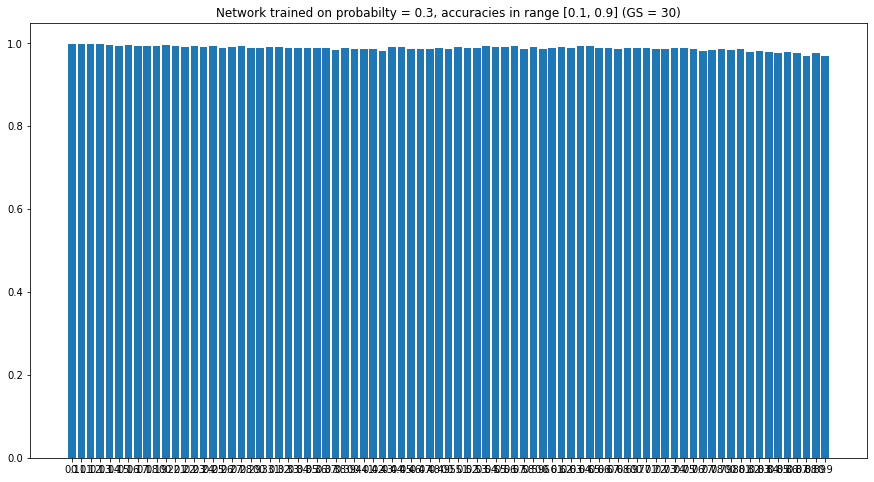
Though there is decline in performance when 1s occur too frequently its still above 95% mark

Edge cases are still tricky, pun intended; left: target, right: predicted

Though it has the correct idea of where to look for it does not generate the proper result; left: target, right: predicted
🤔 Some extensions and limitations
There are some very clear limitations for using this like lack of specificity i.e. we cannot get the exact output always because neural networks are still function approximators and not exact code. But I think this is solvable because we humans can store large set of rules in our neural networks and so we should be able to theoratically store this in computer.
Even in this case we still have trained our network by providing 1000s of sample, but what in situation where do not have such data or generate data by simulation. In most cases we do have the data but sometimes the organisation might have a pre-concieved notion and it may have never happened. Issue that comes with lack of data is that a particular BR might have been put in place as a failsafe. As seen above sparsity is still an issue, when an algorithm has not seen the samples it is unable to learn it properly.
Another thought might be that do we even need something like this? And my argument is that this is needed because then we can change it for good, implementing proper procedures, there will nonetheless issues that come from lack of explainability and approximations but pros will still outweigh the cons. Particularly less critical tedious operations will find benefit from this and in future this might allow for optimisation to take place and god knows we need that to happen.
This is still at naive stage but if you have any comments do reach out to me at bonde.yash97@gmail.com