Transfer Learning in RL using Generative Models
Attempt at RoR 2.0 #5
INDEX
Introduction
OpenAI's RoR 2.0 (Requests for Research 2.0) has always been the benchmark for difficult problems in deep reinforcement learning research. It has 9 problems with increasing difficulty levels, starting with warmup problems like training an LSTM network to solve XOR PROBLEM to making Olympiad Inequality Problems Database (PDF), something worthy of a PhD. Now that I am in my final year and am preparing to pursue my masters in the US, I need to have a good research paper in hand. Enter the long alluring RoR 2.0.
This list was released about a year ago on 31st January, 2018 and I read it the next day. I tried to solve the warmup problem and was able to do it partially, but problem 5 was what stuck in my head for a really long time. I knew I had to use the transformer network and needed to learn quite a bit for that, so the first thing I did was teach myself how to build that and wrote this and this blog posts and also trained the model. Once I was comfortable enough to implement and test research papers on my own I decided to learn RL in details and taught myself RL by watching courses from David Silver. This not only gave me a perspective on things but also made me realise that Applied Reinforcement Learning is what I want to do in life (*bold statement*).
Anyways coming back to the point, the problem statement had following steps to follow:
What is transfer learning
According to Wikipedia, transfer learning is a research problem in machine learning that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem. This is a bit different from traditional learning where the AI has to learn one task efficiently while here it needs to have a knowledge bank from the tasks previously learned to use it in other tasks.
There can also be different levels transfer learning required, 'shallow' and 'deep'. Shallow TL exmaple would be playing 2D chess and then moving onto 3D chess is relatively simple, as the knowledge learned need to be more or less moved to a three dimensional board. On the other hand deep TL example would be physics, where knowledge learned from wide variety of domains (mechanics, electrical, thermodynamics, relativity) needs to be incorporated to newer domains (quantum mechanics, general relativity).
Generating Trajectories
The first part in this problem is generating the trajectory database on 11 good Atari Games. Though there are a tonne of Atari Games that are available I settled on the following: VideoPinball, Boxing, Breakout, Star Gunner, Robotank, Atlantis, Crazy Climber, Gopher, Deamon Attack, Name This Game, Krull. The reason I chose those was because of their high reward distribution making learning tasks easier (these are also the games with largest score in DQN paper) also we use the latest version *-v4 because of this reason. Now that the games are finalised we can talk about the data collection part, which is going to be tricky because we have to collect the data in MDP style i.e. each data point will effectively be (s, a, s', r, ... ) where s is the initial state, a is the action taken, s' is the new state and r is the reward from the environment and other values. Each state is a 87x87 RGB image, so you get the idea of amount of effort required for data collection that has to be done. I will add updates to this once I start writing the scripts.
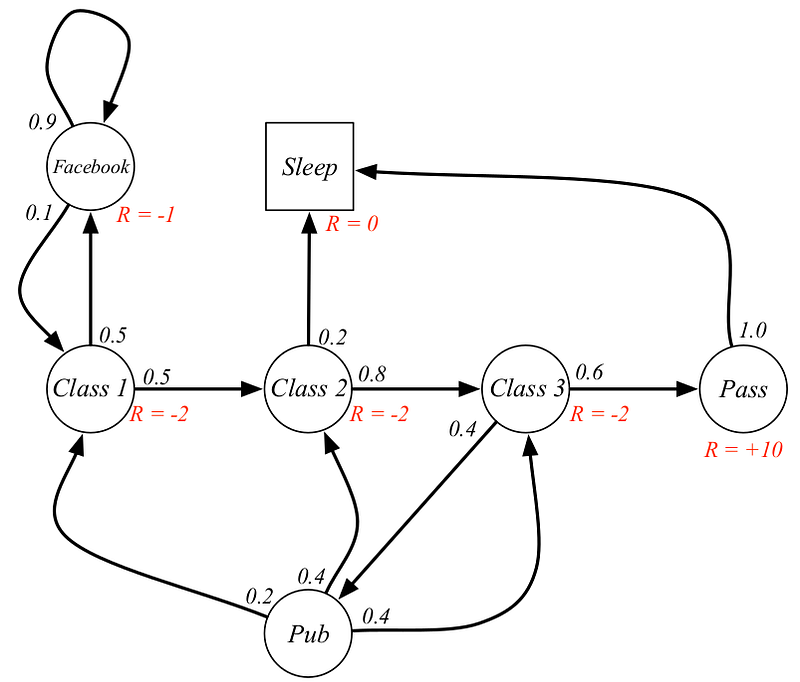
An MDP example for a student. The numbers on the line represent probability of taking that path, while R tells the reward for being in that state
Fitting a generative model
In a very interesting paper, the researchers describe how they combined the Generative Adversarial Network and Q-Learning. I wanted to do something similar but never understood what the input to generator network should be. In classical approach to the GAN the input was a noise latent vector while in their model they feed the Q-value Q(s,a) as the input to the generator. This resulted in scores that were considerably higher in a few games than the DQN Algorithm.
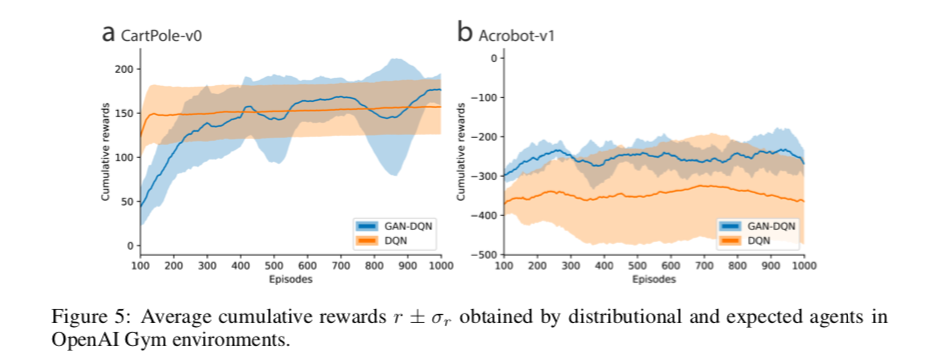
Results from the paper
The problem statement approaches this problem by stating that it needs to fit a generative model like the transformer. With this the authors are actually discussing about this particular paper, in which the transformer network was trained in two different ways such that it had higher understanding due to unsupervised pre-training (fancy words, meaning MLE) followed by supervised fine-tuning.
My approach is similar with having generative pre-training and then supervised fine tuning, the first step is to train a generative network (GAN or otherwise) on the database of 10 games and then fine tune on the 11th
NEXT STEPS
There are a few generative models that use RL algorithms like REINFORCE, to train the network to generate sequences namely SeqGAN and ORGAN. I need to see if we can use something from this kind of model, using MCTS looks interesting and promising and has been used in some of the top AI players of the world.
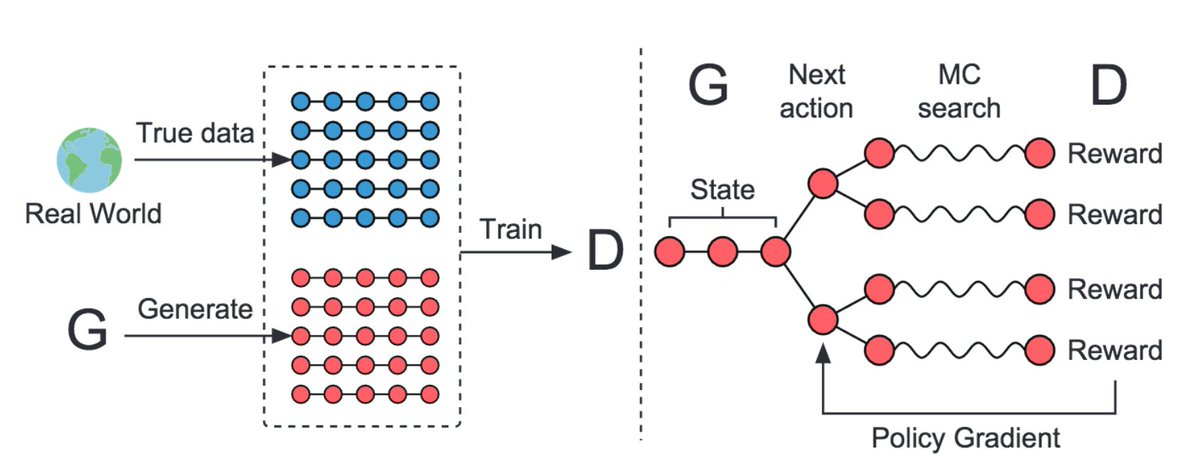
SeqGAN uses MCTS and so do many of the world's top AI players including DeepMind's AlphaGo
PS: Few more things about the Website
Unlike other blogs posts that I write this one will be kept on getting modified as I proceed on this task, I might have to redesign a few elements here and there to make it more appealing. I think this is a really cool way to communicate with the people. Unlike the block form of current social media and internet, e.g. Medium stories and series are all in the block they are not interactive, I need to add that here. I will keep adding updates to the respective sections once I start writing the code.